
1 - Data
This dataset, serving as a cornerstone for initial investigations, consists of two core elements:
product information and customer reviews.
With 8494 records featuring distinct product IDs, the product information segment offers comprehensive details, while the customer reviews section encompasses a significant 1,091,248 entries.
All analyses and models in this study operated on these datasets, focusing specifically on products within the ”Skincare” category.
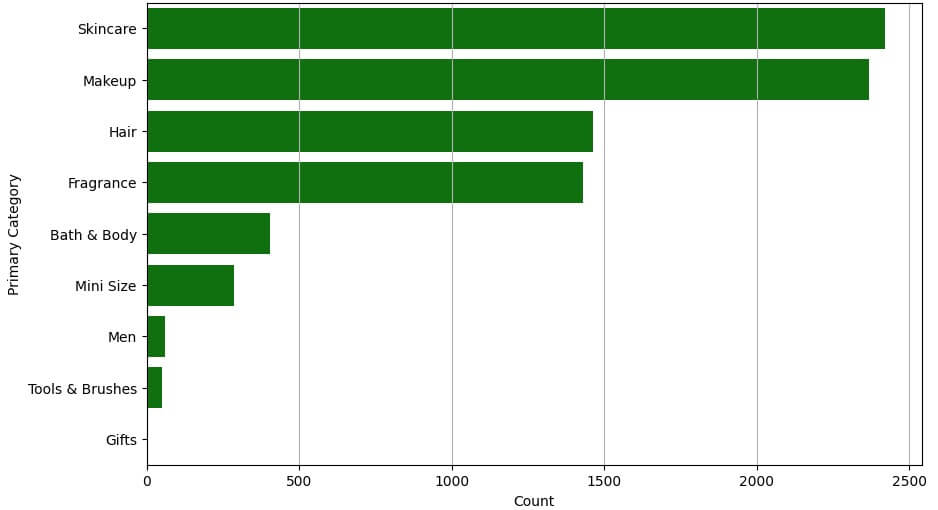
The distribution of primary categories within the original dataset of product information can be observed in the images which showcases a significantly larger number of values compared to other categories.

2 - Data Preprocessing
Besides, the product information dataset included the ”highlights” column, acting as a descriptive categorical feature for each individual product. By employing the one-hot encoding technique, each term within this column underwent conversion into a distinct binary vector, thereby amplifying the dataset’s usability for each product.
Consequently, the generation of 85 new binary features for each product enables efficient product filtering on the platform, leading to an enhanced user experience by facilitating easier searchability.
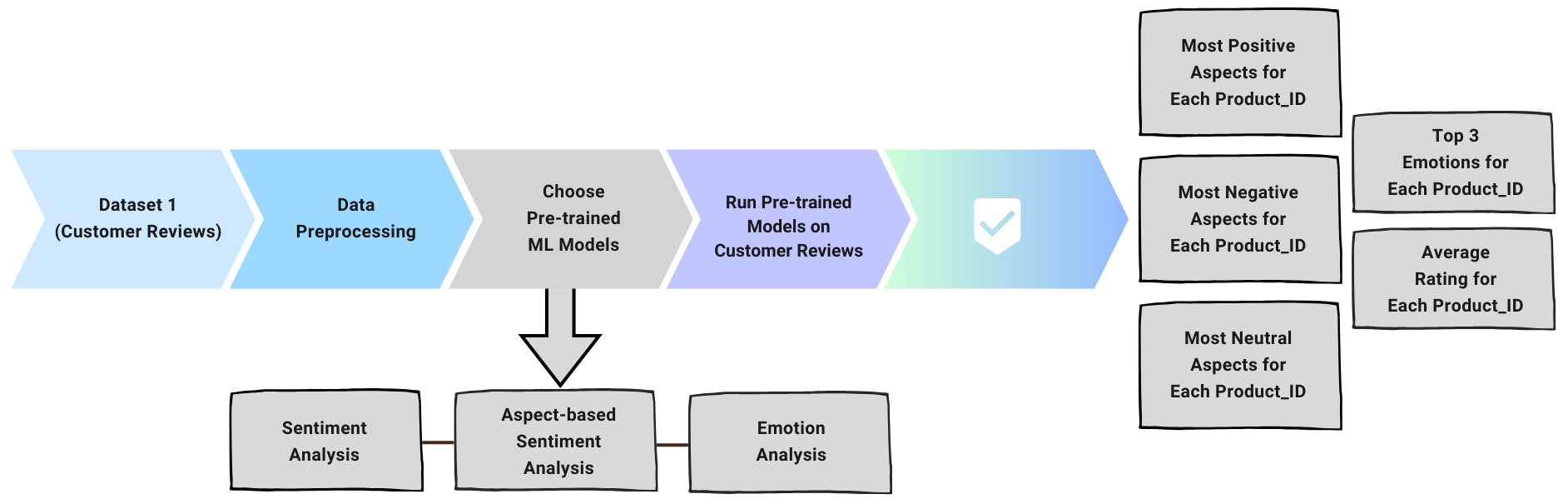
Initially, a crucial part of this framework involves handling initial customer reviews to derive valuable insights about products.
The part one revolves around preprocessing the customer review dataset, including data cleaning to ensure consistency, removal of unnecessary columns, eliminating duplicates, hashtags, URLs, and emojis, and merging the ”review title” and ”review text” columns into a single entity.
Subsequently, three high-quality pretrained models sourced from the Huggingface website, backed by academic papers, are selected.
These models are employed to perform various text classification tasks on the textual data, encompassing sentiment analysis, emotion recognition, and aspect-based sentiment analysis.

3 - Experiment
Regarding pre-trained models operating on the dataset, initially the ”roberta- base-go-emotions” pre-trained model was employed.
However, during the model feeding process on the original dataframe, a runtime error arose, indicating that ”the expanded size of the tensor (737) must match the existing size (514) at non-singleton dimension 1”. The target sizes were [1, 737], whereas the tensor sizes were [1, 514].
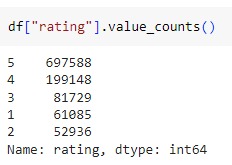
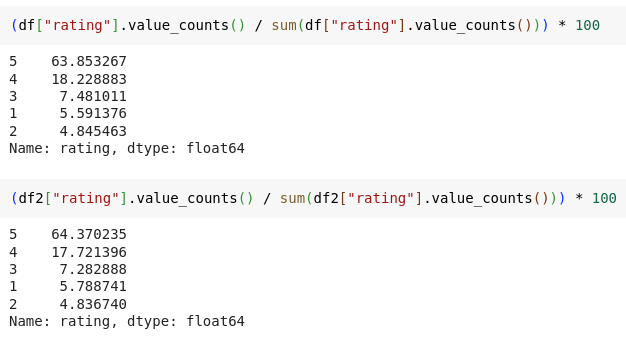
Consequently, to tackle this issue, rows exceeding the threshold were removed. Specifically, 176,311 rows with a sequence length greater than 512 were dropped, resulting in 916,175 remaining rows.
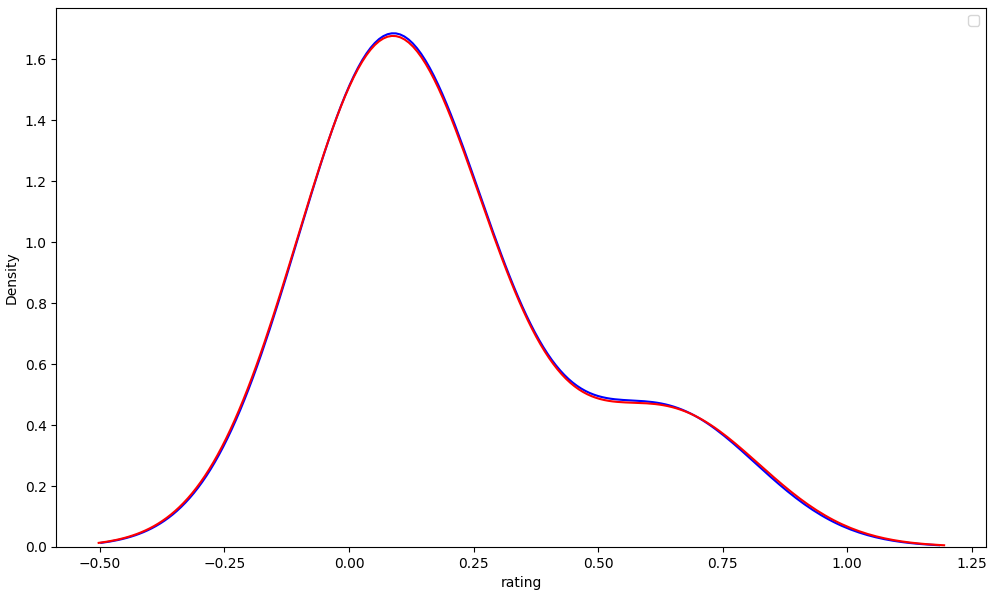
Proceeding, the subsequent rows are regarded as part of the upgraded dataset. An examination was conducted to determine the similarity between the initial and updated datasets, focusing on potential biases introduced by the manipulation.
The below diagram illustrates a nearly uniform distribution of values across each rating class, with minor variations. This consistency reinforces the reliability of the second dataset, indicating the absence of significant bias.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,7))
# blue is original data
sns.kdeplot(df["rating"].value_counts() / df["rating"].count(), color='blue')
# red is modified data
sns.kdeplot(df2["rating"].value_counts() / df2["rating"].count(), color='red')
plt.legend()
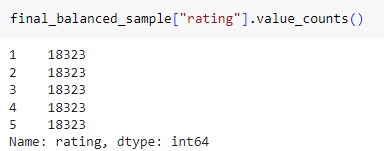
4 - Data Sampling
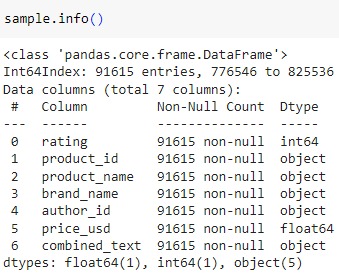
Given the substantial size of the customer reviews dataset, a 10% fractional sample was generated for system input.
5 - ML Models
Multiple text classification machine learning models were executed on the customer review sample representing 10% of the dataset, consisting of 91,615 rows. The outcomes of these analyses are detailed below:
Sentiment Analysis
After conducting research among all the available machine learning models in academic papers for sentiment analysis, RoBERTa emerges with the highest average accuracy, scoring 92% for two-class tasks and 79.1% for three-class tasks for sentiment analysis.
Notably, it outperforms other models in accuracy across 12 out of 19 datasets. This underscores the capability of larger models, pre-trained on vast text corpora, to capture intricate language nuances crucial for sentiment classification.
Emotion Analysis
A pretrained RoBERTa-based model is utilised for this task. This model trained from roberta-base on the GoEmotions dataset which boasts the largest dataset in its category, with 58,000 Reddit comments labelled for 27 emotions or Neutral gathered from diverse English subreddits.
This model is a multi-label classification model with 28 ‘probability’ float outputs for any given input text. Typically a threshold of 0.5 is applied to the probabilities for the prediction for each label.
The evaluation metrics are more meaningful when measured per label given the multi-label nature (each label is effectively an independent binary classification) and the fact that there is drastically different representations of the labels in the dataset.
With a threshold of 0.5 applied to binarize the model outputs, the accuracy metric is around 90%.
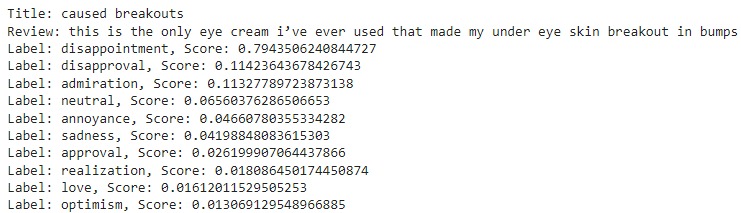
Aspect-based Sentiment Analysis
This technique enhances the understanding of reviews by directly targeting sentiments rather than language structure.
In the given example, “I love the pizza at this restaurant, but the service is terrible,” two aspects are evident: “pizza” and “service.” The sentiment towards “pizza” is positive, whereas the sentiment towards “service” is negative.
ABSA is vital for both users, who seek information before purchasing or booking services, and companies, which aim to understand user satisfaction to improve products.
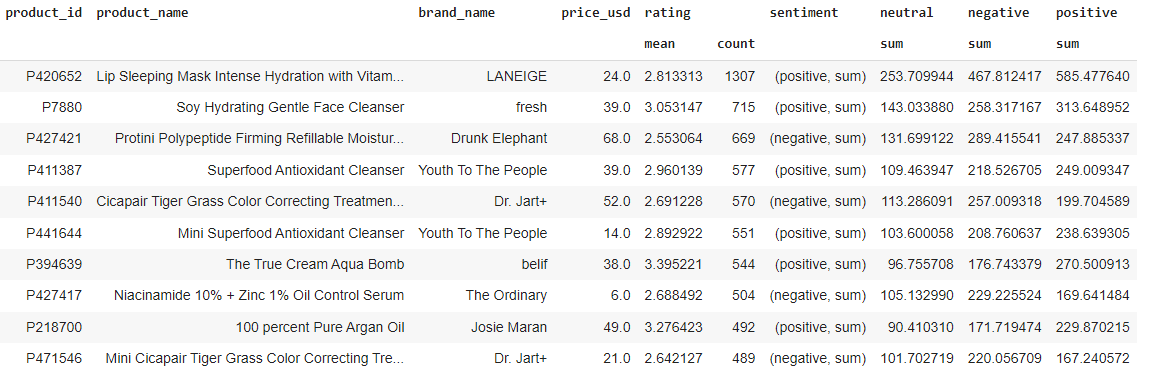
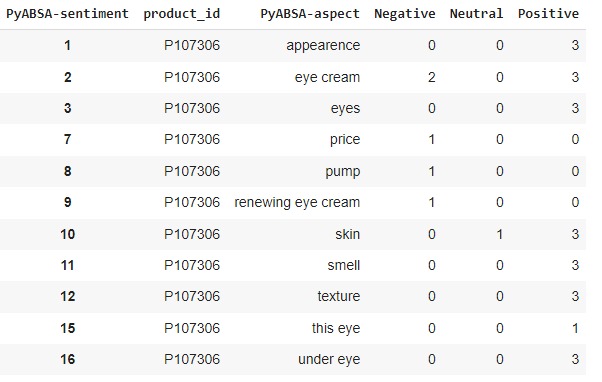
Analysing aspects can greatly assist companies. For instance, if a company finds that users highly praise the camera of their latest smartphone, they might opt to incorporate a similar camera into their forthcoming models but with slightly diminished specifications.
This approach is undertaken with the intention of reducing production expenses while simultaneously enhancing sales potential. In the table above, one product is analysed in terms of aspects that customers have written and their frequency.

University of Gloucestershire
- +900 hours teaching
- Teaching practical sessions for undergraduates & postgraduates
- Delivering theoretical modules
- Coordinator for Cyber and Data Science Symposium (CyDaSS)
- Mathematics for Data Science
- Python coding
- Web Development
- Network Security
Ecopoetikon Project
- Designed the website layout and structure
- Integrated back-end functionality using Laravel and PHP
- Created and managed database
- Developed data collection strategies
- Monitor user behaviour and engagement
Nabta Health
- Set up analytical tools
- Collect users demographic, transactional, behavioural, and health data from website, Android and iOS applications
- Optimise website performance and UX using a data-driven approach
- Build machine learning models to analyse textual content

Worked with numerous other companies across various sectors

- Natural Language Processing (NLP)
- Digital product design and development
- Project Management
- Problem solving
- Python
- SQL
- PowerBI
- Google Analytics
- Google Data Studio
- Apache Spark
- Excel
- Back-end frameworks (Django, Laravel)
- Front-end frameworks (Flutter, Bootstrap)
- Prompting
- PHP/WordPress
- VSCode, Jupyter, Git